Accelerating Solution of Generalized Linear Models by Solving Normal Equation using GPGPU on a Large Real-World Tall-Skinny Data Set
T. Sang, R. Kobayashi, R. S. Yamaguchi, T. Nakata “Accelerating Solution of Generalized Linear Models by Solving Normal Equation using GPGPU on a Large Real-World Tall-Skinny Data Set”, IEEE 31st International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), pp.112-119, Oct. 2019 .
- Machine learning algorithm becomes more popular, recently
- Training time gets longer when the data size grows and needs to be reduced.
- Especially, in the IoT data analysis field, it is common to see a very tall-skinny dataset (e.g. 4×107 by 27).
- E.g location history, physical activity history, shopping history, …
- We wanted to speed up the machine learning algorithm on a real-world application which uses the Generalized Linear Model (GLM)
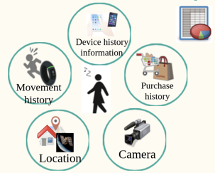
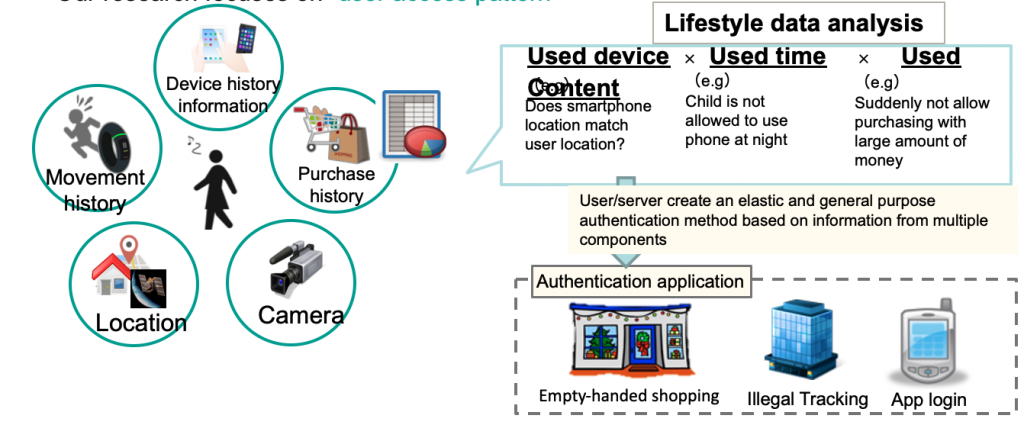
Lifestyle authentication(*)
(*) 小林 良輔, 疋田 敏朗, 鈴木 宏哉, 山口 利恵.“行動 センシングログを元にしたライフスタイル認証の提 案”, コンピュータセキュリティシンポジウム 2016 論文集, 2016(2), pp.1284-1290 (2016)
- A technology which makes use of lifestyle information to identify the user
- By Yamaguchi Laboratory @ Social ICT Research Center, the University of Tokyo
- Using information from smartphone device and website without explicit user activity
- As a result of convenience and security,
- increase number of users and aim to a safer society
- Our research focuses on “user access pattern”
Training execution profiling

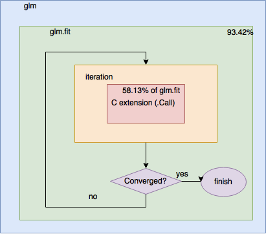
- Total time complexity: O(m×n2×k) (m=2,719,348: no. of samples, n=27: no. of features, k=7: no. of iterations)
- Total execution time: 112.79 seconds
- Training mostly depends on the “.Call” which is called in many iterations
- C extension “.Call” routine solves the Linear Least Squares equation (LS equation)
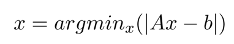
- The standard library uses canonical Linpack library with minor modification
- The first step is to rewrite the “.Call” routine with GPU APIs
- Speedup upper bound limit of this step: 2.2 times
- This is base step for further future optimization
Acceleration comparison between two approaches
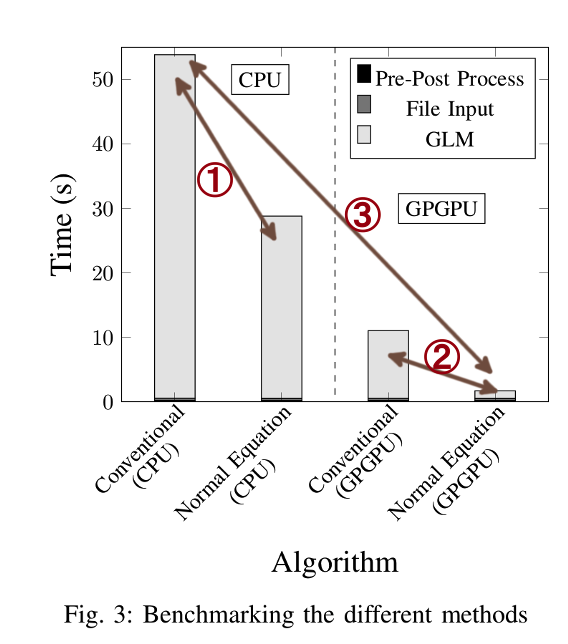

- In the conventional algorithm, GPGPU reduces running time by 4.9x
- Folded with 6.4x time of Normal Equation
- Leading to 31.3x time speedup in total